Earlier this week, the Strait of Hormuz closed. Within minutes, video footage from across the region flooded social media, news channels, and intelligence feeds. Vessel fires in port. Crowds gathering in city squares. Infrastructure under stress. The volume of visual information was immediate, overwhelming, and scattered across dozens of sources in multiple languages.
For most organizations, the response is the same: scramble analysts to monitors, begin manually reviewing footage, try to piece together what is happening and where. It takes hours. By the time a coherent picture emerges, the situation on the ground has already moved on.
BlackVidINT processed the footage at machine speed under analyst direction. No manual triage. The system ingested video from open sources, analyzed every frame, geolocated the content, assessed threat levels, and mapped the entire conflict theatre — all within minutes of the first footage appearing.
144 Locations, Zero Analysts
The result was a complete location intelligence map spanning the Middle East conflict theatre, with 144 distinct locations identified and plotted from video analysis alone. Each pin on the map represents a geolocated video source, automatically categorized by threat level using a heat map overlay that distinguishes between low, medium, and high-risk areas.
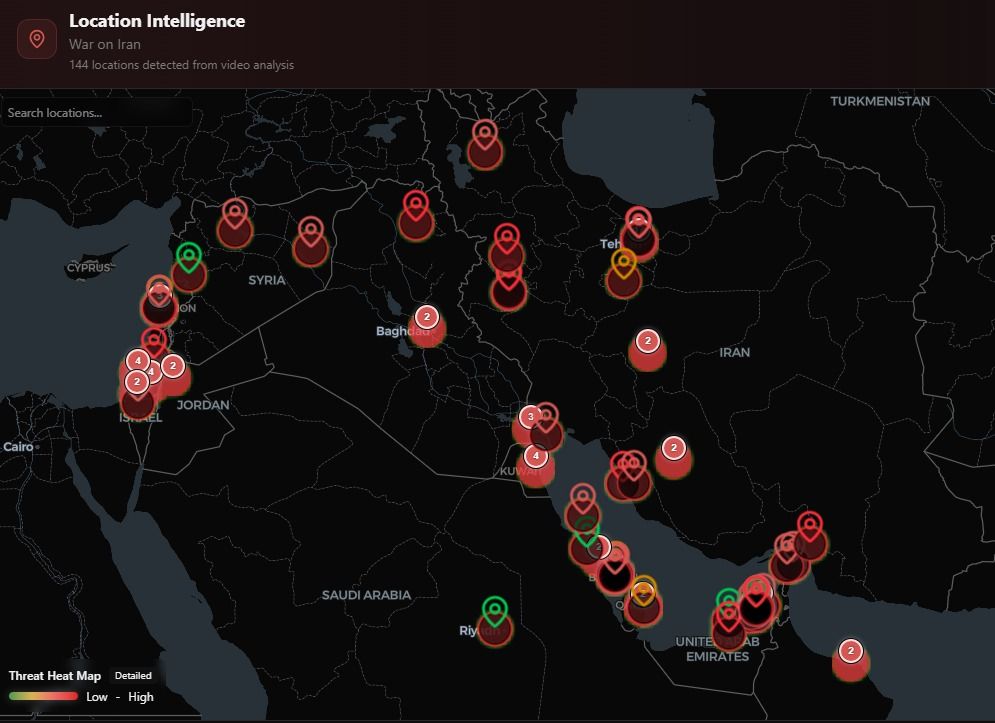
This is not a manually curated map. Every location was derived from visual analysis of the video content itself — identifying landmarks, architectural features, signage, terrain, and other geographic indicators, then cross-referencing against known locations to produce precise coordinates. The system accomplished in minutes what would take a team of geospatial analysts hours or days.
From a 23-Second Clip to Precise Coordinates
One of the videos circulating showed a large crowd gathered in what appeared to be a city square in Iran. The footage was 23 seconds long, shaky, shot on a mobile phone, with no metadata and no geotag. For a human analyst, identifying the location would require recognizing the architecture, researching possible matches, and cross-referencing with satellite imagery.
BlackVidINT identified the location as Naqsh-e Jahan Square in Isfahan (coordinates: 32.65340, 51.67760) by recognizing multiple landmarks visible in the frame: the Shah Mosque (Masjed-e Shah), Ali Qapu Palace, and Khaju Bridge in the background, along with distinctive Safavid-era arched architecture with turquoise domes. The system simultaneously generated a threat heat map for the immediate area and assessed the crowd dynamics.
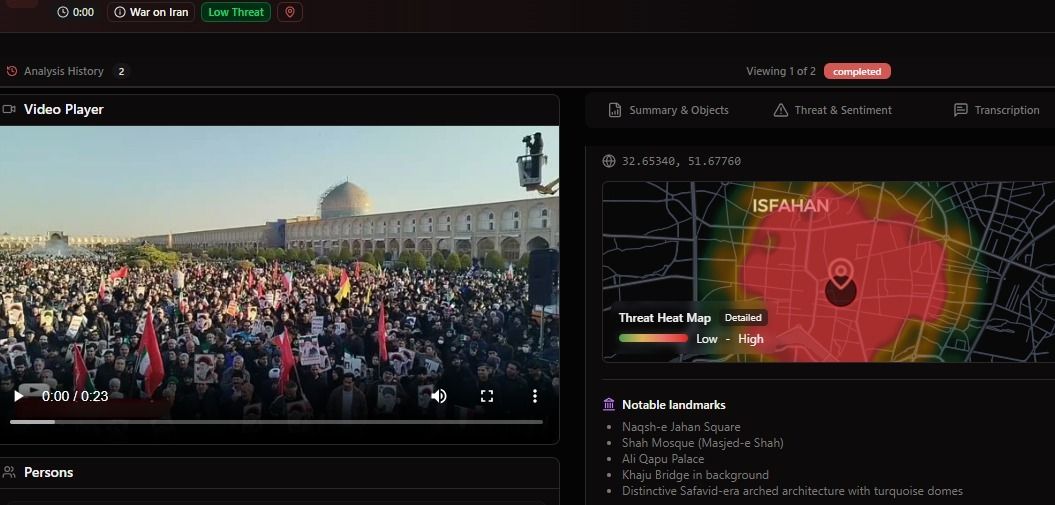
This capability — extracting precise location intelligence from unstructured, untagged video — is what separates automated video intelligence from traditional surveillance. The system does not need GPS coordinates embedded in the file. It reads the visual environment the way a trained analyst would, but at machine speed and across every incoming feed simultaneously.
Automated Maritime Threat Assessment
The crisis produced maritime footage as well — vessel fires, port incidents, and shipping disruptions across the Persian Gulf. BlackVidINT processed these videos through its threat analysis pipeline, producing structured intelligence output for each piece of footage.
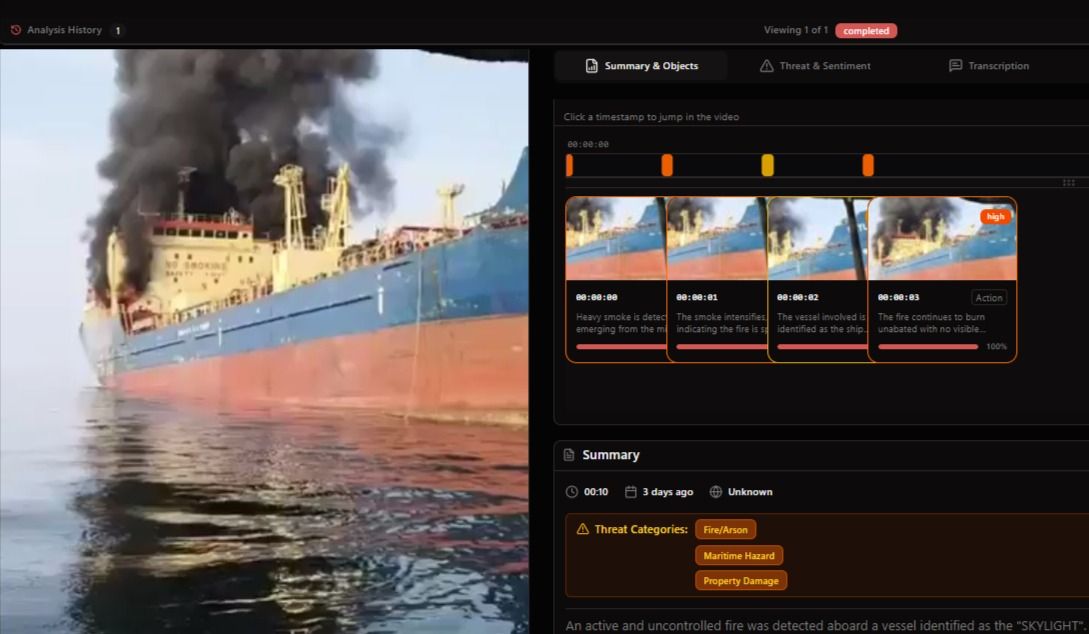
For a video showing a vessel fire, the system produced a frame-by-frame analysis: detecting heavy smoke emerging from the vessel at the first timestamp, tracking fire intensification across subsequent frames, identifying the vessel involved, and flagging the incident with threat categories including Fire/Arson, Maritime Hazard, and Property Damage. The entire analysis completed in seconds.
The threat assessment went deeper. The system automatically flagged the incident as CRITICAL based on the combination of an uncontrolled large-scale fire at critical port infrastructure, the absence of visible firefighting or emergency response, intensifying fire conditions, and the potential for hazardous material release. It identified specific risk factors including infrastructure damage, environmental hazard, and public safety risk.
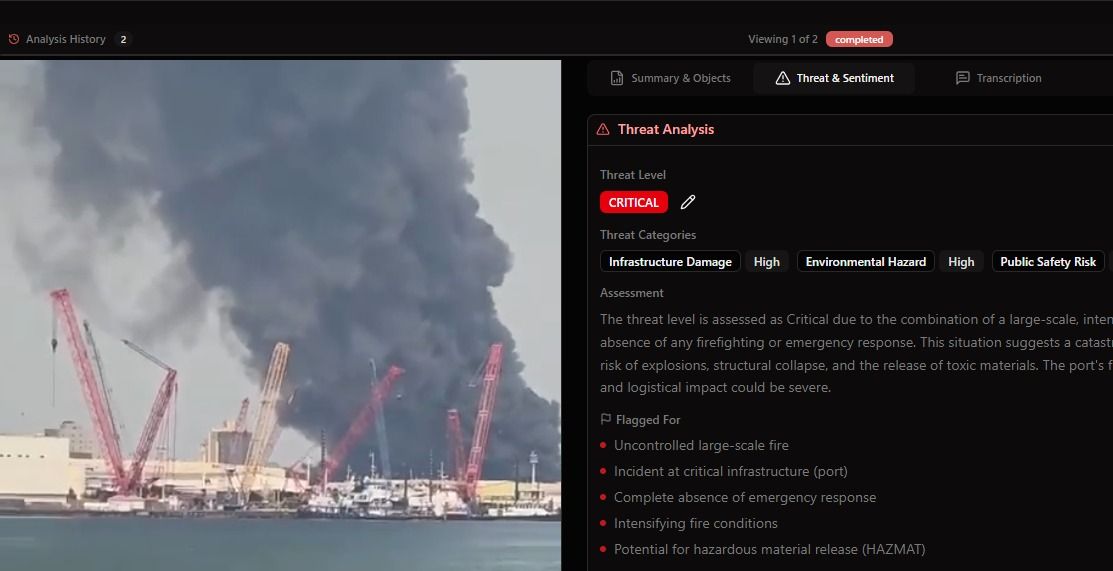
This structured output — threat level, category tags, narrative assessment, and specific flagged indicators — is immediately actionable. It is the kind of analysis that would normally require an experienced analyst spending 30 to 60 minutes reviewing footage, consulting reference materials, and writing up an assessment. BlackVidINT produces it automatically for every video it processes.
The Real Bottleneck Is Not Data
The Strait of Hormuz crisis is a useful illustration of a broader pattern in intelligence operations. The bottleneck is never the availability of information. During any significant event, video floods in from social media, news agencies, surveillance systems, and citizen journalists. The problem is organizational capacity to process it fast enough to matter.
The gap between a video being recorded and a decision being made on the basis of its content — that is where operations succeed or fail. When that gap is measured in hours because human analysts must manually triage, review, geolocate, and assess each piece of footage, the intelligence arrives too late to inform the decisions it was supposed to support.
BlackVidINT collapses that gap. Every video processed in near-real-time. Every location identified. Every threat assessed. Every output structured and searchable. The system does not eliminate the need for human judgment — it ensures that human judgment is applied to finished intelligence rather than raw footage.
What This Means Operationally
For agencies monitoring regional crises, the operational implications are significant:
- Situational awareness at speed: A complete map of 144 geolocated video sources across a conflict theatre, produced within minutes of the first footage appearing, provides commanders and analysts with an immediate operational picture.
- Threat prioritization: Automated CRITICAL/HIGH/MEDIUM/LOW threat assessments allow decision-makers to focus attention where it matters most, rather than reviewing footage sequentially.
- Geolocation without metadata: The ability to pinpoint locations from visual content alone means that even raw, untagged footage from social media becomes a structured intelligence source.
- Scalable analysis: Whether the system is processing 10 videos or 10,000, the analysis quality and speed remain consistent. Human analyst teams cannot scale this way.
- Structured output: Every analysis produces standardized threat categories, narrative assessments, and geolocated data that feeds directly into broader intelligence fusion workflows.
From Passive Monitoring to Active Intelligence
Traditional video intelligence is reactive. Footage is collected, stored, and reviewed when an analyst gets to it. The Hormuz incident demonstrates what becomes possible when video intelligence is fully automated: the system actively processes every incoming source, produces finished intelligence, and delivers it to decision-makers before they even know to ask for it.
This is the operational model that BlackVidINT was built for. Not surveillance in the traditional sense — not cameras pointed at fixed locations waiting for something to happen — but the ability to turn any video source, from any origin, into structured, geolocated, threat-assessed intelligence at machine speed.
When the next crisis breaks, the question is not whether video will be available. It always is. The question is whether your organization can process it fast enough to act on what it reveals.